Racetrack

Racetrack
In recent years, deep learning and especially deep reinforcement learning (DRL) have been applied with great successes to the task of learning near-optimal policies for sequential decision making problems. Supervised learning, in the context of decision making mostly called imitation learning (IL) is based on labeled training data, while reinforcement learning is trained through interacting with a simulated environment.
In Tracking the Race Between Deep Reinforcement Learning and Imitation Learning we aim at an in-depth study of empirical learning agent behavior for a range of different learning frameworks. We train several different agents on the Racetrack domain and compare both, their success rate and their behavior.
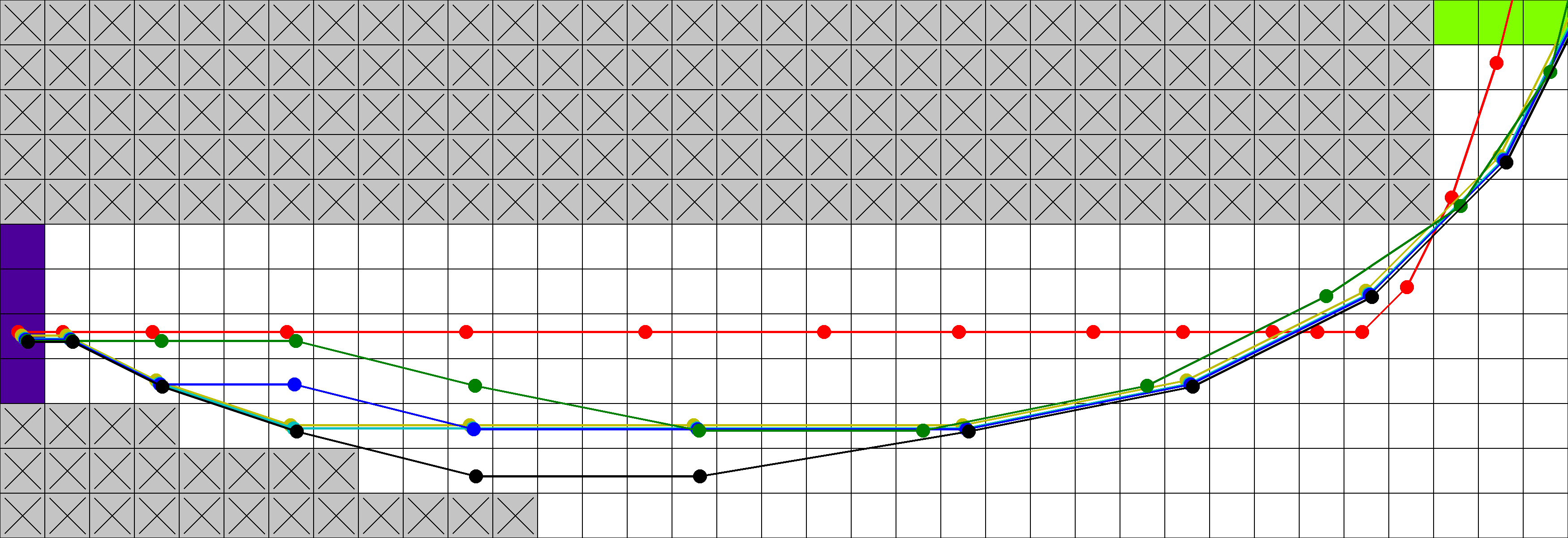
Amongst other things, we find that, even though it is based on optimal training data, imitation learning leads to unsafe policies, much more risky than those found by RL. Upon closer inspection, it turns out that this apparent contradiction actually has an intuitive explanation in terms of the nature of the application and the different learning methods: to minimize time to goal, optimal decisions navigate very closely to dangerous states. This works well when taking optimal decisions throughout – but is brittle to (and thus fatal in the presence of) even small divergences as are to be expected from a learned policy. We believe that this characteristic might carry over to many other applications beyond Racetrack.